一、概述

32路同步数据采集系统可以完成32路数据的同步采集、存储以及实时信号处理等功能,适用于实验室振动状态在线检测、噪声检测、温度试验、环境试验、雷管引爆延迟时间检测等应用。
32路同步数据包括单个板卡通道之间的同步和多个板卡之间的同步,同步后的数据先存在板载DDR3,再通过PCIe接口把数据传输到上位机,如果采集的是瞬态信号,可以使用Standard模式,可以把数据都存储在板载DDR3上,但要求采集的数据不能超过板载DDR3存储容量;如果采集的是连续信号,可以使用FIFO模式,数据可以一边存储在DDR3上,一边把数据传输给上位机,存储的时间的长短受限于磁盘容量的大小。
PCIe高速采集存储系统由数据采集模块、高速数据存储模块、GPU实时处理模块、便携式工控机等部分组成。可以实现信号的实时采集存储,并且通过调用Window API的方式实现了比一般方式更快的数据存储速度。
二、应用方向
具备多次触发的连续数据流模式
可长时间进行雷达信号仿真和模拟
具备多次触发的连续数据流模式
触发间底死区时间(<80ns)
时域和频域分析
高级显示模式
连续数据流存储
超高的数据传输速度(>3.4GB/s)
高采样率和高分辨率
时域和频域分析
低噪声模拟信号调理电路
低噪声与高分辨率
高SNR(>90dB)与SFDR(>105dB)
上百个同步通道
高SNR(>90dB)与SFDR(>105dB)
功能齐全的模拟信号调理电路
5GS/s采样率与宽带宽
板载分块统计、峰值检测功能
三、术语说明
四、环境说明
硬件平台
微星X99A SLI PLUS主板
Intel i7-5820k 处理器
金士顿 8GB DDR4 内存x4

Spectrum M2i.4912:8通道,16bit,10MS/s采样率AD采集卡
±200mV到±10V软件可调增益设置
50欧姆或1M欧姆输入阻抗
板载高稳定度采集时钟发生器,支持外时钟和外触发同步输入
PCIe2.0 x1接口
512MB板载内存
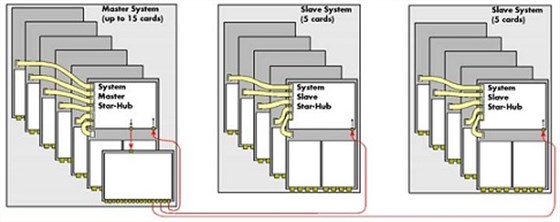
Star-Hub实现多板卡同步:

NVIDIA GeForce GTX 980
Maxwell架构
支持CUDA 并行处理
CUDA处理器核心达2048
4TB RAID0磁盘阵列
连续存储速度可达1.2GB/s
磁盘阵列由4块1TB三星固态硬盘组成,每个固态硬盘支持大500MS/s(实测)的写入速度,组成RAID0阵列后支持大1.2GB/s(实测)的写入速度。RAID0磁盘没有奇偶数目的要求,数据被平均分割存储到多个磁盘上,总的读写速度就是磁盘数量乘以单个磁盘的读写速度,缺点在于一块磁盘损坏,则整个磁盘阵列即坏,数据无法被修复。
软件平台
Control Center:Control center是spectrum公司的专有的控制采集卡校准、license激活、底层kernel控制的软件。启动control center有Kernel Register Settings,可以设置底层kernel开辟的物理连续地址空间,用于DMA大数据量存储使用。
我们知道,目前的操作系统中,非常严格的把物理存储空间、内核存储空间、上层用户存储空间区分开来。
Windows操作系统对内存的管理是按照4kByte来进行的。
对于软件来说,申请到的虚拟内存都是通过内存管理单元每4kByte来进行分配的。对于上位机软件来说,分配1个很大的内存空间,在虚拟内存上是连续的,但是在物理地址上有可能是很多个独立的4kByte组成的。
当使用虚拟的内存来进行DMA传输数据的时候,这个过程是非常复杂的。
因为,DMA传输数据是直接通过物理地址传递的,这样DMA传输就得通过每个独立的4kByte的页来进行传输,这样每次DMA传输的数据都是在不同物理地址4kByte页上切换到降低DMA传输的效率。
Spectrum kernel driver:Spectrum公司通过自己底层驱动,可以通过软件向底层申请开辟一段物理地址连续的地址空间,申请完,需要重启电脑,重启电脑,在PC机boot的过程中,需要多花费平时的80%的启动时间。
五、总体设计
硬件总体框架:
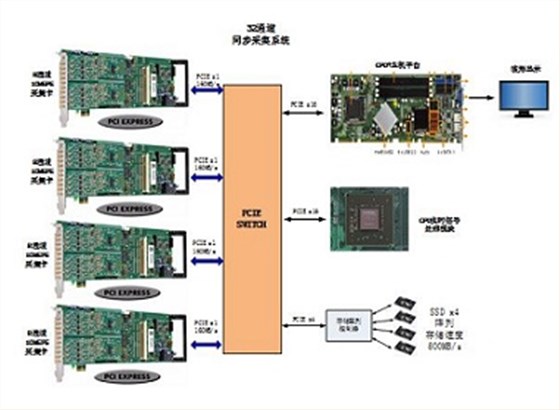
数据采集系统在FIFO模式下数据的传输存储速度主要受限于PCIE接口的传输速度与磁盘的写入速度。
本系统数据采集卡采用PCIex1 Gen2.0接口,数据传输速度可达160MB/s。采集卡为16bit,采样率高为10MS/s,这时单个采集卡在FIFO模式下需传输的数据量为:
16bit/2*10MS/s*8=160MB/s
恰好达到PCIe接口的极限速度。采集到的信号在写入磁盘时总的数据量为:
160MB/s*4=640MB/s
写入速度超过单个固态硬盘的写入速度,但使用RAID0阵列时,则可以满足写入的需求。
六、高速存储模块
限制文件存储速度的终瓶颈还是磁盘的固有特性,我们所能做到只是改善软件的实现去逼近硬盘的极限读写速度。一般windows系统粘贴拷贝文件的时候,影响存储速度地方就在于它利用了windows文件缓存机制,当你拷贝一个大文件时,windows会根据你要拷贝的文件大小缓存很大一部分到系统缓存,这时候你会看到系统缓存瞬间飙涨,机器性能大大降低,所以我们要避免使用windows缓存机制,并且尽量读写连续的文件块。
利用Window API读写文件
一般来说,我们操作一个windows I/O句柄用的是windows文件读写系列API:CreateFile, ReadFile, WriteFile等,这些API不仅可以读写文件句柄,所有的I/O设备句柄都能通过这些API来操作。比如socket描述符, 串口描述符,管道描述符等。通过设置他们的参数,我们可以选择以不同的方式操作IO。
对于读写速度,重要的是dwFlagsAndAttrib参数,FILE_FLAG_NO_BUFFERING指示系统不使用快速缓冲区或缓存,当和FILE_FLAG_OVERLAPPED组合,该标志给出大的异步操作量,因为I/O不依赖内存管理器的异步操作。然而,一些I/O操作将会运行得长一些,因为数据没有控制在缓存中。
当使用FILE_FLAG_NO_BUFFERING打开文件进行工作时,程序必须达到下列要求:
1. 文件的存取开头的字节偏移量必须是扇区尺寸的整倍数。
2. 文件存取的字节数必须是扇区尺寸的整倍数。例如,如果扇区尺寸是512字节。程序就可以读或者写512,1024或者2048字节,但不能够是335,981或者7171字节。
3. 进行读和写操作的地址必须在扇区的对齐位置,在内存中对齐的地址是扇区。尺寸的整倍数。一个将缓冲区与扇区尺寸对齐的途径是使用VirtualAlloc函数。
它分配与操作系统内存页大小的整倍数对齐的内存地址.这块内存在地址中同样与扇区尺寸大小的整倍数对齐。程序可以通过调用GetDiskFreeSpace来确定扇区的尺寸。
高速采集存储配置
为了实现高速采集存储,此处用到了windows多线程编程,一个线程接收板卡采集到的数据,一个线程负责写文件。为了保证存储文件的速度需要连续写入大文件,通过申请两个大小相同的buffer,执行ping-pang写文件操作。
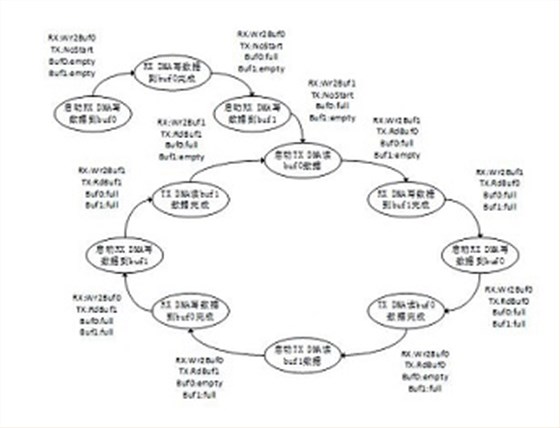
Buf0和Buf1收发数据为ping-pang原理,Buf0和Buf1的状态为empty和full,当数据通过TX DMA读出后,Buf的状态置为empty,当数据通过RX DMA写入后,Buf的状态置为full。RX DMA和TX DMA的状态分别有WrBuf0,WrBuf1,RdBuf0,RdBuf1,OpCmpt,NotStart,TXHungry0,TXHungry1几种状态。
对于ADC接收数据方向,RX DMA写buf0产生完成中断后,首先开始写buf1操作,然后建立写buf0的DMA接收链表。同样当RX DMA写buf1产生完成中断后,首先开始写buf0操作,然后建立写buf1的DMA接收链表。
对于PCIE发送数据方向,TX DMA读buf0产生完成中断后,首先开始读buf1操作,然后建立读buf0的DMA发送链表。同样当TX DMA读buf1产生完成中断后,首先开始读buf0操作,然后建立读buf1的DMA发送链表。
根据PC机实际内存大小,设置相应的buffer大小,buffer需要尽可能大。通过API工程里面的宏定义设置buffer的大小。

另外几个与高速存储相关的API如下图:
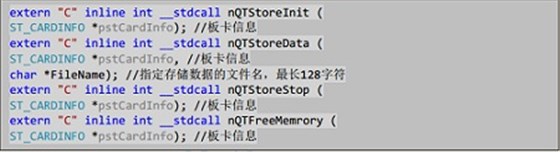
nQTStoreInit输出参数为板卡信息块,通过调同此接口申请好Ping-Pang buffer,由于运行时间较长,所以建议放置在配置过程中执行。nQTStoreData创建好文件,并且开始采集存储。在执行了一段时间的采集后可以通过调用nQTStoreStop来停止采集和存储。值得注意的是程序通过Ping-Pang机制存储所以会导致后得到的文件大小是Buffer大小的整数倍,但是会保证上位机获取到的数据全部都存入到文件中。为了实现循环开始存储,停止存储操作,避免此过程中内存的重复申请与释放导致降低效率,把内存释放的操作以下API中:
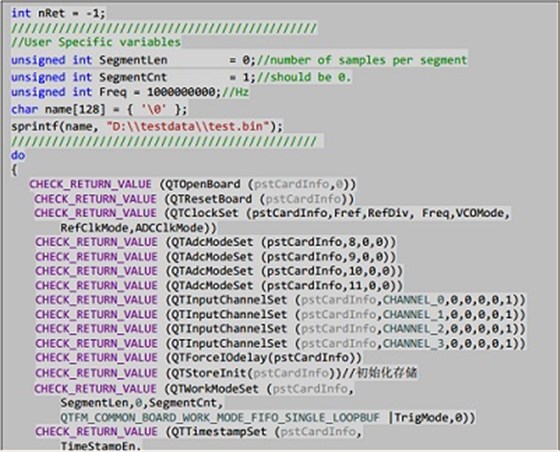
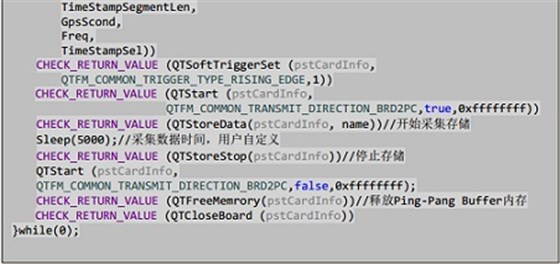
在程序运行的结尾,通过调用nQTFreeMemrory来释放Ping-Pang buffer的内存。这样就完成了从打开板卡进行数据采集到数据存储到工控机硬盘中的全过程。
与一般存储方式速度对比
一般存储方式通过调用C语言中的fwrite进行写数据的操作,但这样的方式在数据量巨大的情况下与Writefile这种调用Windows API方式进行对比时速度差异明显,在使用Writefile方式进行大量数据写入时速度可逼近硬盘的写入速度。
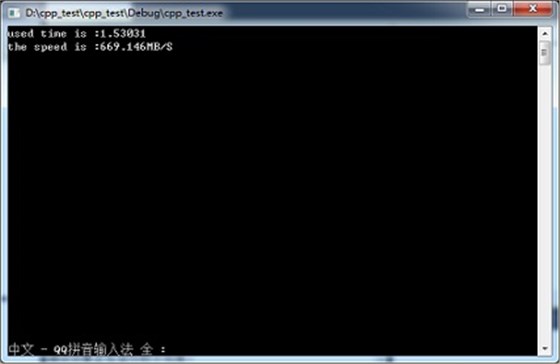
下图为写入1GB数据时使用fwrite进行写数据操作时实测的速度:

下图为写入1GB数据时使用WriteFile进行写数据操作时实测的速度:
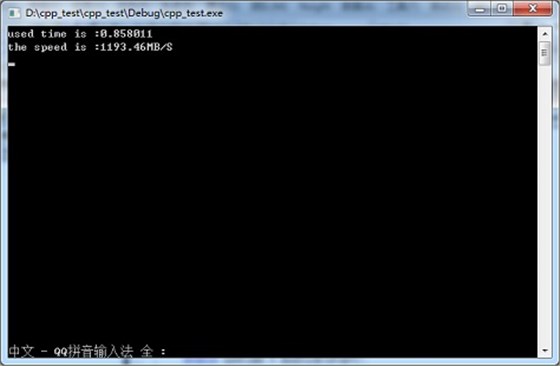
由图中测试数据可知,使用WriteFile进行写数据时速度可达1193.46MB/s,远远快于使用fwrite时669.146MB/s的写入速度。当写入的数据量越大时,WriteFile的优势越明显,直至逼近磁盘阵列的极限速度。
七、GPU分析处理模块
NVIDIA GPU介绍
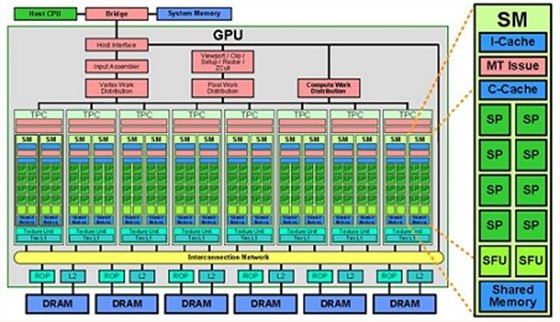
图形处理单元CPU英文全称Graphic Processing Unit,GPU是相对于CPU的一个概念,NVIDIA公司在1999年发布GeForce256图形处理芯片时首先提出GPU的概念。GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,主要是并行计算部分。CPU具有强大的浮点数编程和计算能力,在计算吞吐量和内存带宽上,现代的GPU远远超过CPU。
使用NVIDIA CUDA Fast Fourier Transform Library提供了一个简单计算FFT运算的接口,而不用用户自己实现FFT算法。
GPU内存管理
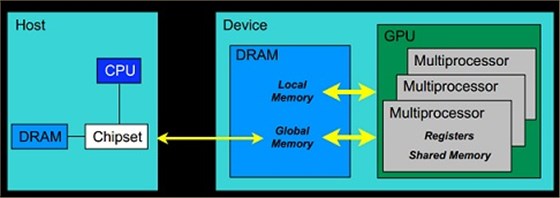
Host:将CPU及系统的内存称为主机
Device:将GPU及GPU本身的显示内存称为设备
cudaMalloc(): 与C语言中的malloc函数一样,用户函数分配线性内存空间。
cudaMemcpy():与C语言中的memcpy函数一样,只是此函数可以在主机内存和GPU内存之间互相拷贝数据。
cudaFree():与C语言中的free函数一样,只是此函数释放的是
cudaMalloc:分配的内存,主要用于释放线性内存空间。
CPU与GPU进行FFT分析速度对比
lCPU FFT分析
MATLAB对10M Sample的数据进行FFT运算,时间0.594697s,如下图:
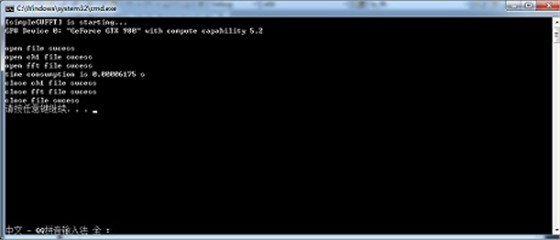
lGPU FFT分析
使用GPU进行FFT计算,FFT点数10M Sample,运行时间0.00006175s。
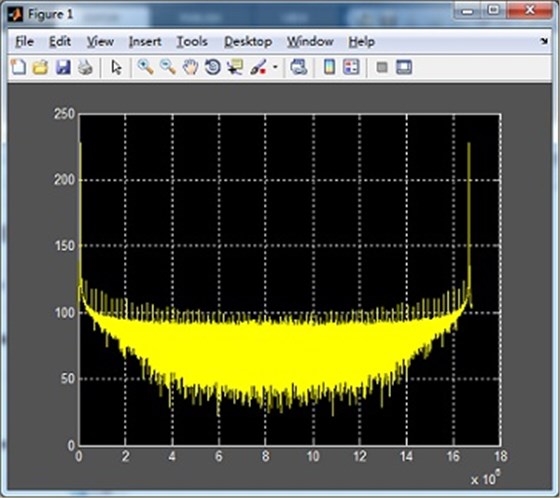
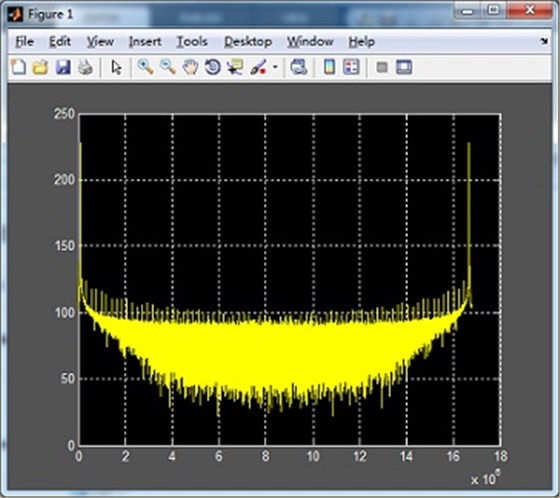
对GPU FFT运算之后的结果,10M个实部real和10M个虚部imag,用MATLAB进行仿真,如下图:

 电话咨询
电话咨询 产品中心
产品中心 在线留言
在线留言 关于坤驰
关于坤驰 

